If you are in Prague this summer, and wanting to satiate your Factorio cravings, you can stop in to the National Library of Technology Prague, where Factorio is loaded onto 150 computers for all to play. Entry is free for all visitors Monday to Friday 08:00 - 22:00 until the 31st of August. The PC's are running Linux (Fedora), loaded with a custom build of the game HanziQ put together, and you can host LAN servers and play with your friends.

On the 23rd of July we will be hosting our own Factorio LAN party at the library starting at 16:00 CEST (Prague time), so you can come along and play with us. It is advised to bring your own set of headphones if you are going to attend.
As we started to modernize our rendering backend, the absolute must have was to make it at least as fast as the old one. We had the chance to do things however we wanted, so we were excited about the capabilities newer APIs unlocked for us, and we had lot of ideas how to draw sprites as fast as possible.
But first, there is no need to reinvent the wheel, so let’s see how Allegro makes the magic happen. Allegro utilizes sprite batching, which means it draws multiple sprites that use same texture and rendering state, using a single command sent to the GPU. These draw commands are usually referred to as draw calls. Allegro draws sprites using 6 vertices, and it batches them into a C allocated buffer. Whenever a batch ends, it is passed to the OpenGL or DirectX drawing function that copies it (in order to not stall the CPU) and send the draw call.

That looks pretty reasonable, but we can’t do the exact same thing, because in DirectX 10, there are no functions for drawing from C-arrays directly, and it is mandatory to use vertex buffers. So our first version created vertex buffer to which current batch was always copied for use in a draw call, and we would reallocate a buffer with a larger size if the current batch wouldn’t fit. It was running quite fine, probably not as fast as Allegro version, and it lagged noticeably whenever the vertex buffer would need to be resized.
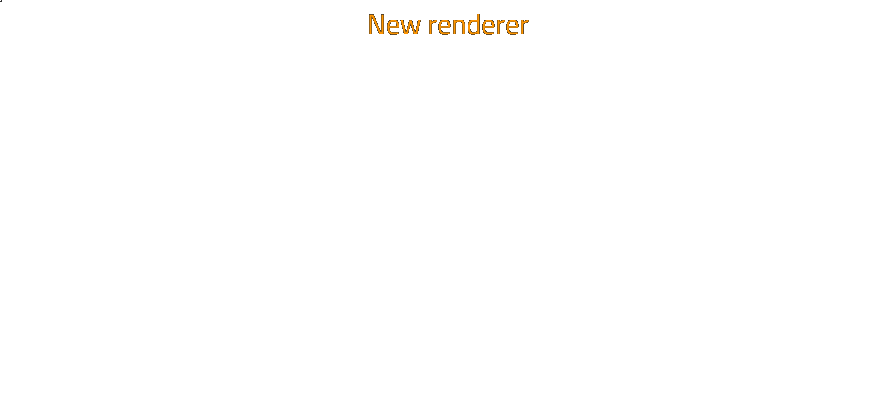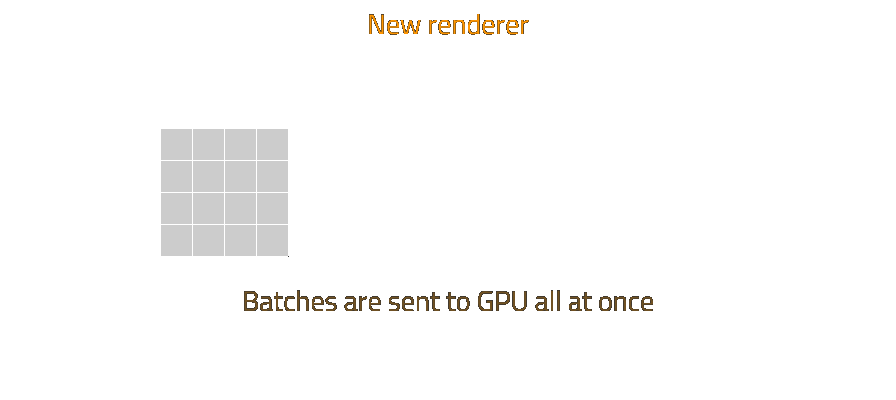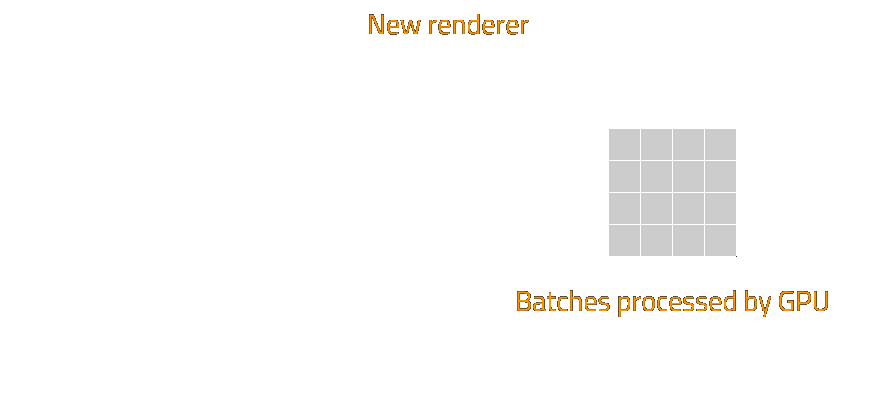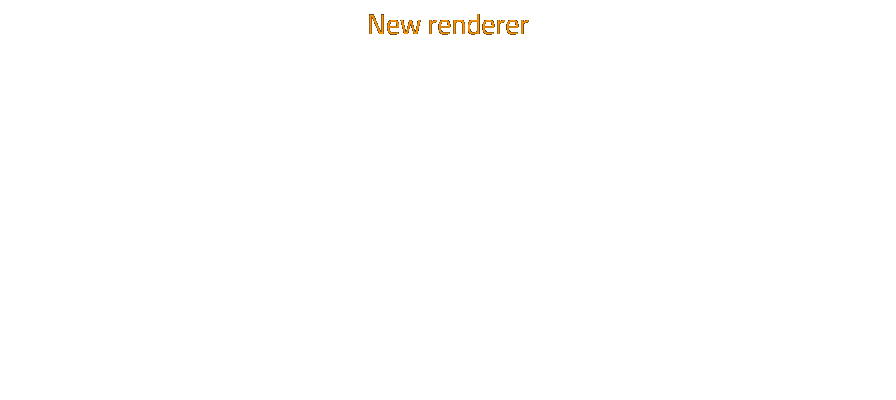
After reading some articles, for example optimizing rendering in Galactic Civilizations 3 and buffer object streaming on the OpenGL Wiki (which was very helpful), it became clear that the way to go is to have a vertex buffer of fixed size, and keep adding to until it is full. When we finish writing a batch to the buffer, we don't send a draw call right away, we write where this batch starts and ends into a queue, and keep writing into the buffer. When the buffer is full, we unmap it from system memory, and send all the queued draw calls at once. This saves on the expensive operation of mapping and unmapping the vertex buffer for each batch.
As we were trying to figure out how to serve data to the GPU in the most efficient way, we were also experimenting with what kind of data to send to GPU. The less data we send, the better, and Allegro was using 6 vertices per sprite with a total size of 144 bytes. We wanted to do point sprites which would require only 48 bytes per sprite and less overall maths for the CPU to prepare a single sprite. Our first idea was to use instancing, but we quickly changed our mind without even trying, because when researching the method, we stumbled upon this presentation specifically warning against using instancing for objects with low polygon count (like sprites). Out next idea was to implement point sprites using a geometry shader.
![]()
We tried it, and it worked great. We got some speedup due CPU needing to prepare less data, but when doing research how different APIs work with geometry shaders, we found out that Metal (and therefore MoltenVK) on macOS doesn’t support geometry shaders at all. After more digging, we found an article called Why Geometry Shaders Are Slow. So we tested using the geometry shader on a range of PCs in the office, and found that while it was faster on PCs with new graphics cards, the older machines took a noticeable performance hit. Due to the lack of support on macOS and the possible slowdown on slower machines, we decided to drop the idea.
It seems the best way to do point sprites is to use a constant buffer or texture buffer to pass point data to a vertex shader, and expand points into quads there. But at this time we already have all the optimizations mentioned in the first part, and the CPU part of rendering is now fast enough that we have put the point sprite idea on ice the for time being. Instead, the CPU will prepare 4 vertices per sprite with a total size of 80 bytes, and we will use a static index buffer to expand them to two triangles.
The following benchmark results are from various computers. The benchmark rendered a single frame at max zoom out (about 25,000 sprites) 600 times as fast as possible without updating the game, and the graph shows the average time to prepare and render the frame. On computers with integrated GPU there was little improvement because those seem to be bottlenecked by the GPU.
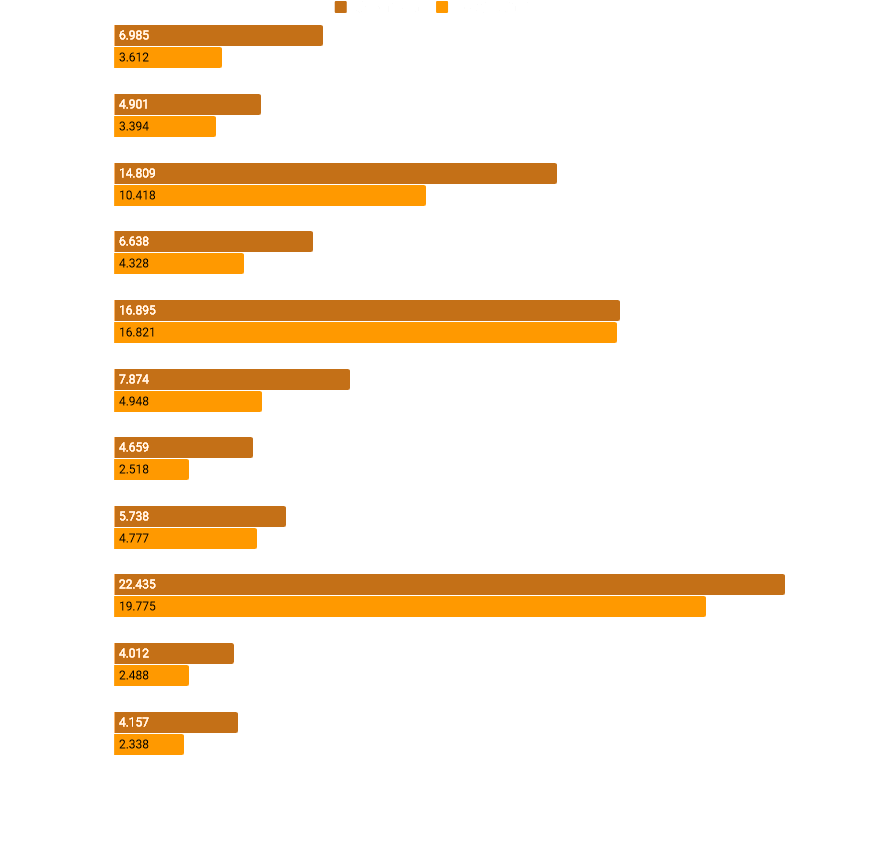
We also noticed higher speed-ups on AMD cards compared to nVidia cards. For example in my computer I have a GTX 1060 6GB and Radeon R7 360. In 0.16 rendering was much slower on the Radeon than on the GeForce, but with the new renderer the performance is almost the same (as it should be because GPU finishes its job faster than the CPU can feed it draw commands). Next we need to improve the GPU side of things, mainly excessive usage of video memory (VRAM), but more on that topic in some future Friday Facts...
As always, let us know what you think on our forum.